Introduction
Yusheng Zheng, Yu Tong
eBPF is a revolutionary technology that originated in the Linux kernel, enabling sandboxed programs to run within the operating system's kernel. It is used to safely and efficiently extend the kernel's capabilities without altering its source code or loading kernel modules.
In this blog, we are excited to introduce a new open-source user-space eBPF runtime: https://github.com/eunomia-bpf/bpftime. bpftime further expands the capabilities of eBPF, allowing existing eBPF tools and applications, such as BCC tools, bpftrace, Deepflow, etc., to run in non-privileged user space without any code modifications, while using the same libraries and toolchains as kernel eBPF.
bpftime not only provides dynamic tracing or extension mechanisms like Uprobe and system call tracepoints, but also offers an order of magnitude performance improvement over kernel Uprobe. Moreover, like kernel eBPF, it requires no manual code instrumentation or process restarts. bpftime supports inter-process eBPF maps through user-space shared memory, while being compatible with kernel eBPF maps, enabling seamless operations with kernel eBPF infrastructure. Additionally, it includes high-performance LLVM JIT/AOT compilers for various architectures, as well as a lightweight JIT and interpreter for x86. Through performance data and real-world examples, we will demonstrate how bpftime can be effective in the real world and provide insights into its future development. We hope bpftime will bring unprecedented performance and flexibility to system monitoring, analysis, and extension. We also introduced the design and implementation of bpftime at the Linux plumbers 23 conference[2].
eBPF: System Extension from Kernel to User Space
eBPF (extended Berkeley Packet Filter) has evolved from a simple network packet filtering tool into a versatile system-level extension technology. Since the inception of BPF in the 1990s, eBPF has significantly enhanced its functionality through an expanded instruction set and direct interaction with kernel data structures. After joining the Linux kernel in 2014, eBPF became a powerful bytecode engine, widely used in performance analysis, security policies, and other areas. With the growing complexity of computing environments, eBPF's real-time data collection and analysis capabilities have become crucial in modern computing, especially in traffic control, load balancing, and security policies.
Although eBPF was initially designed for the kernel, its tremendous potential in user space, coupled with the kernel's GPL LICENSE restrictions, led to the development of early user-space eBPF runtimes like ubpf[3] and rbpf[4]. These runtimes allowed developers to execute eBPF bytecode outside the kernel, breaking free from GPL license restrictions and offering a more intuitive and convenient debugging environment. However, writing programs for ubpf and rbpf might require a specific, not fully kernel-compatible toolchain, and they only had limited single-threaded hash maps implementations, making it difficult to run actual eBPF programs. Additionally, ubpf and rbpf are essentially eBPF bytecode virtual machines that still require glue code to compile and link with other user-space programs for practical use, and they did not offer dynamic tracing functionality.
In practice, user-space eBPF has been explored and applied in fields like network processing, blockchain, and security. For example, Oko and DPDK eBPF support demonstrate the flexibility and performance advantages of eBPF in network data processing. The Solana project utilized eBPF to implement a JIT compiler, supporting the execution of blockchain smart contracts. The eBPF for Windows project extended eBPF functionality beyond Linux, showcasing its potential for cross-platform compatibility. These applications not only demonstrate eBPF's powerful system extension capabilities but also highlight its significance and wide applicability in the modern computing domain. For further discussion, refer to our previous blog: https://eunomia.dev/blogs/userspace-ebpf/.
Why We Need bpftime
Due to the core role of operating system kernels and the high demands for stability and security, innovation and evolution in operating system kernels tend to be slow. This is the original intention behind eBPF: to extend the kernel's functionality without changing its source code, thereby bringing more innovative application scenarios[5]. This is also the impact we hope bpftime will have: exploring more development possibilities with the safety and ecosystem brought by eBPF, without changing user-space program code, and compensating for the potential shortcomings of current kernel-space eBPF and other user-space extension solutions.
Limitations of Kernel-Space Implementation of User-Space Tracing (Uprobe) and System Call Tracing
Uprobe is a powerful user-level dynamic tracing mechanism that allows developers to perform dynamic instrumentation in user-space programs, such as at function entry points, specific code offsets, and function return points. This technology is implemented by setting breakpoints at designated locations, such as using the int3 instruction on x86 architecture. When the execution flow reaches this point, the program traps into the kernel, triggering an event, then executing a predefined probe function, and finally returning to user-space to continue execution. This dynamic tracing method can trace and instrument all processes executing a specific file across the system, allowing for the collection of critical data for performance analysis and fault diagnosis without modifying code, recompiling, or restarting processes.
However, since the eBPF virtual machine executes in kernel mode, the current Uprobe implementation introduces two context switches in the kernel, causing significant performance overhead, especially impacting performance in latency-sensitive applications. As shown in the diagram, Uprobe's overhead is nearly ten times that of Kprobe[5]. On the other hand, Uprobe is currently limited to tracing and cannot modify the execution flow or return values of user-space functions, limiting its use cases to code extension, hot patching, defect injection, etc. Despite this, Uprobe is still widely used in production environments for its non-intrusive user-space functionality tracing, such as tracing user-space protocols like SSL/TLS and HTTP2, monitoring memory allocation and leaks, analyzing garbage collection and language runtimes, and tracking the creation and recycling of coroutines, among other scenarios.
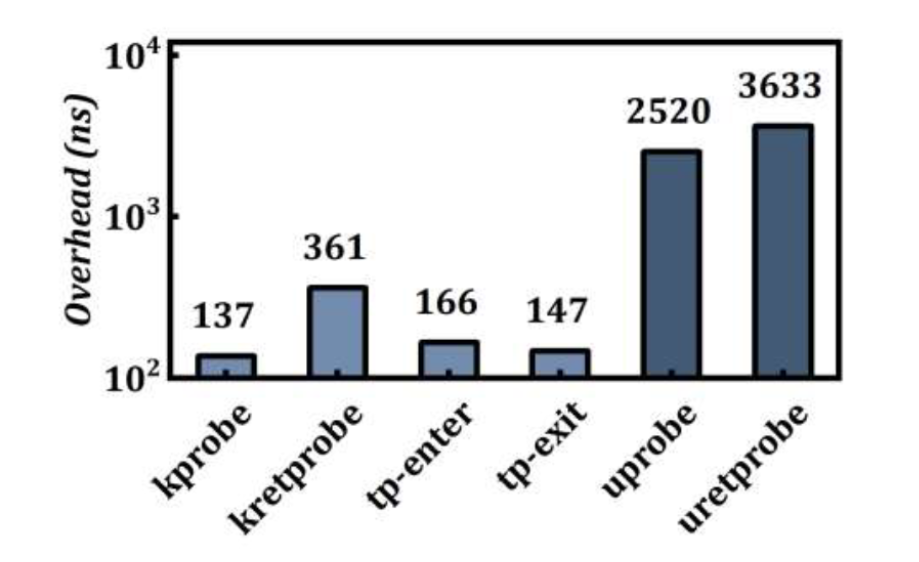
For system call tracepoints, since they are globally visible, additional filtering is required for specific process tracing, such as filtering based on pid, cgroup, etc., in eBPF[6], which also brings some additional overhead to other processes that do not need to be traced.
Limitations of Kernel-Space eBPF in Terms of Security and Extensibility
eBPF running in kernel mode has its limitations in terms of security and extensibility. On one hand, eBPF programs need to run in kernel mode, meaning they require root privileges, thereby increasing the attack surface and potential risks, such as container escape. Moreover, vulnerabilities in eBPF itself can lead to security issues at the kernel level. On the other hand, while the verifier restricts eBPF programs to ensure safety, this also limits the functionality expansion of eBPF; any new feature or improvement requires modifications to the kernel code. These limitations not only increase the maintenance difficulty of the system but also reduce the flexibility and universality of eBPF.
For kernels without eBPF support (e.g., older systems) or applications in non-privileged containers, user-space eBPF runtimes are a viable alternative, allowing the execution of eBPF programs for tracing, analysis, and extension operations without kernel eBPF support.
Shortcomings of Other User-Space Extension Solutions
Currently, there are other user-space tracing and extension solutions, such as gdb and other tools that use the ptrace mechanism for process tracing and analysis, Wasm, Lua virtual machines that can be used as plugin runtimes, and binary instrumentation tools like Frida for dynamic tracing in user space. However, these solutions have their own limitations.
High Performance Overhead: Traditional tools like gdb use the ptrace mechanism for process tracing. Although they are powerful, they introduce significant performance overhead when analyzing and interacting with other processes. This method frequently pauses and resumes the target process, leading to reduced efficiency. Additionally, ptrace limits the number of processes that can be traced simultaneously in the system, making large-scale distributed tracing infeasible. WebAssembly (Wasm) sandboxes, while offering good flexibility and cross-language support, require strict validation and runtime checks when executing external libraries or procedures, potentially introducing performance losses. In contrast, eBPF offers a more performance-centric strategy, using static analysis and a verifier to ensure safe execution of code on the host without additional runtime overhead. For bpftime, since it embeds the eBPF virtual machine in the function call context of the traced process without extra context switches, it has lower performance overhead.Security Issues: Binary instrumentation tools like Frida provide dynamic tracing capabilities, but this can introduce security issues. The instrumentation code runs in the same process context and can be maliciously exploited. Additionally, code defects in the tracing tools or scripts themselves may cause the traced program to crash, such as accessing incorrect addresses or pointers. In contrast, eBPF can ensure the safety of code through its verifier.Insufficient Visibility: Additionally, for other user-space tracing solutions, these tools typically only offer visibility into single processes and cannot provide system-wide insights. They struggle to capture a global view of kernel-level events or cross-process communications, limiting their analytical capabilities in complex systems. This is why eBPF and other solutions mainly perform tracing in kernel space, allowing for correlated analysis of kernel and user-space events, such as linking layer 7 network packets with kernel-level network events, or associating user-space function call behavior with kernel-level system calls, thus providing more comprehensive analytical capabilities. For bpftime, it can be more than just a user-space virtual machine solution. User-space eBPF can work in conjunction with kernel-space eBPF infrastructure to achieve boundary-crossing analysis and extension capabilities.
For existing other user-space eBPF runtimes, as mentioned earlier, they lack dynamic tracing or extension capabilities, require manual integration, and cannot directly utilize existing eBPF toolchains and applications, which greatly limits their use cases. On the other hand, they cannot work directly with kernel-space eBPF, only offering limited user-space extension capabilities.
bpftime: User-Space eBPF Runtime
User-Space eBPF Runtime Compatible with Existing eBPF Tools and Frameworks
bpftime aims to maintain good compatibility with existing kernel eBPF as a user-space alternative and improvement to kernel eBPF. It also seeks to maximize the use of the rich ecosystem and tools of existing eBPF. For example, bpftime allows the direct use of unmodified bpftrace tools to execute eBPF scripts in user space, tracing system calls or user-space functions:
At the same time, it can run user-space versions of BCC/libbpf-tools such as bashreadline, funclatency, gethostlatency, mountsnoop, opensnoop, sigsnoop, statsnoop, syscount, etc[7]. bpftime constructs eBPF map data structures in user-space shared memory, enabling the analysis and statistics of multiple processes, and supports reporting data to tracing tools through ring buffer, perf buffer, and other means.
bpftime also provides eBPF infrastructure compatible with the kernel in user-space. It can run without needing kernel eBPF and supports some of the kernel's eBPF maps, helpers, dynamic tracing mechanisms, and almost all eBPF instruction sets:

From a security perspective, bpftime provides an eBPF verifier to ensure the safety of eBPF bytecode, preventing malicious code injection or damaging the traced process. bpftime can use the kernel's eBPF verifier or an independent user-space eBPF verifier as an alternative for environments without access to kernel eBPF.
High-Performance Uprobe and System Call Tracing
bpftime supports Uprobe and system call tracing by embedding eBPF programs into the function call context of the traced process through binary rewriting, thus achieving dynamic tracing and extension. This method not only avoids context switching between kernel and user spaces but also collects key data for performance analysis and fault diagnosis without modifying code, recompiling, or restarting processes. Compared to kernel Uprobe, bpftime's Uprobe implementation is more performant and offers more functionalities, such as modifying function return values or altering function execution flows, enabling code extension, hot patching, and defect injection. The performance of user-space Uprobe implemented by bpftime can be an order of magnitude higher than that of kernel Uprobe:
| Probe/Tracepoint Types | Kernel (ns) | Userspace (ns) |
|---|---|---|
| Uprobe | 3224.172760 | 314.569110 |
| Uretprobe | 3996.799580 | 381.270270 |
| Syscall Trace | 151.82801 | 232.57691 |
Using dynamic library injection implemented via ptrace and technologies like LD_PRELOAD, bpftime's eBPF runtime supports tracing during program startup and also allows mounting eBPF probes directly onto multiple running processes. We conducted a test where a probe monitoring the malloc function in libc was loaded using bpftime, and the loading latency was measured. The results showed that bpftime caused the running process to pause for about 48 milliseconds during loading. For comparison, we used the LD_PRELOAD method to load the same extension before the process started and observed a loading latency of 30 milliseconds.
We used the sslsniff tool[8] to trace and analyze SSL encrypted traffic of Nginx in bpftime's user-space Uprobe and compared it with the kernel Uprobe approach, observing a significant performance improvement:
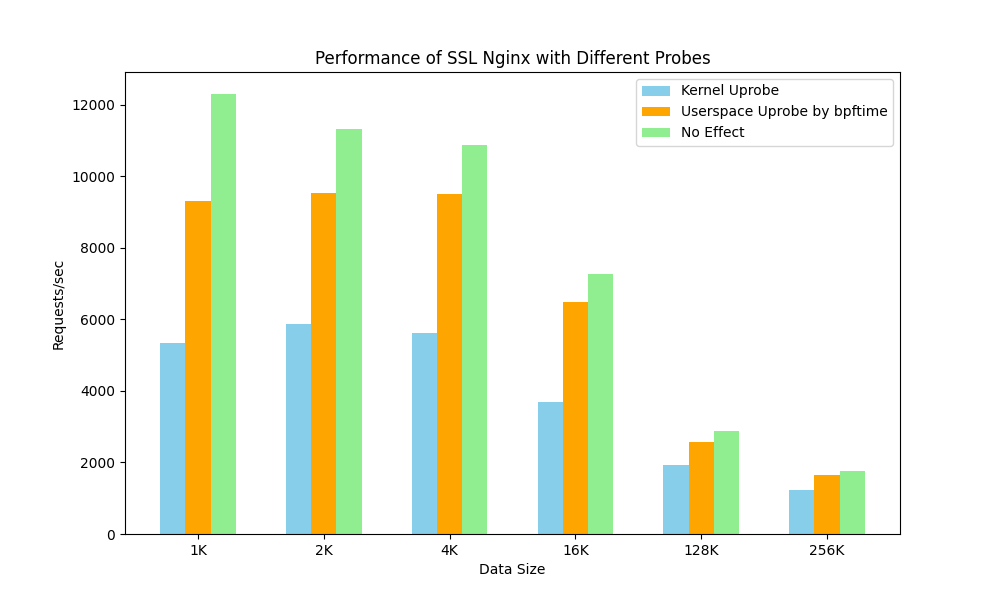
For modern eBPF observability tools, it may be necessary to collect and analyze the same event in both kernel and user-space functions. For instance, an HTTP request might require analyzing both kernel-level network events and user-space function calls to obtain a complete request chain. bpftime's Uprobe implementation can work in conjunction with kernel eBPF kprobes, enabling this kind of cross-boundary analysis capability. Implementing and improving other dynamic tracing mechanisms are also part of our plan.
New eBPF JIT and AOT Compilers
bpftime includes a new LLVM-based eBPF JIT compiler that compiles eBPF bytecode into native machine code at runtime, thereby improving the execution efficiency of eBPF programs. Compared to other user-space eBPF runtime JIT compilers like ubpf and rbpf, and Wasm, the LLVM JIT compiler offers better performance, approaching the efficiency of native code execution. It also provides better cross-platform support, for example, supporting architectures like RISC-V. We conducted a simple performance comparison and analysis[9]:
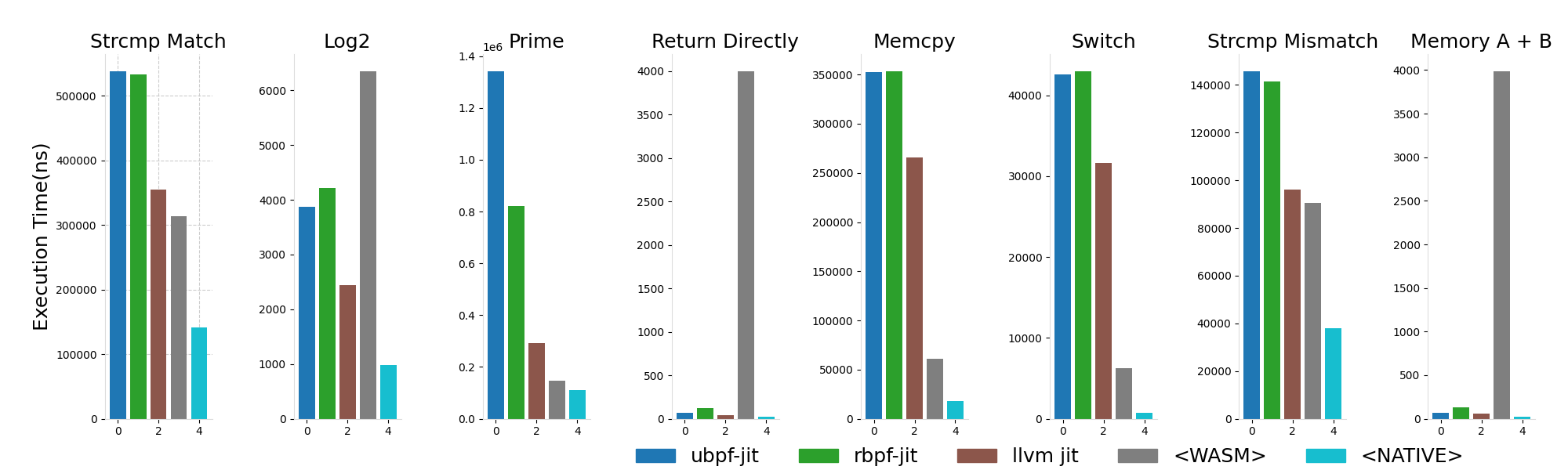
In addition to JIT, bpftime also includes an AOT compiler, which allows eBPF bytecode to be pre-compiled into machine code files for specific architectures after verification. This can be particularly useful for deployment and use in embedded systems, significantly reducing the time for compilation at startup.
More Exploratory Use Cases and Future Developments
Beyond extending previous Uprobe and system call tracepoints, bpftime can also be used for other exploratory use cases, such as:
Fault Injection: Using the kernel-compatible bpf_override_return() helper[10], bpftime can modify the Syscall return values of processes, block specific Syscalls, or modify and replace specific function calls in certain types of eBPF programs. This enables fault injection capabilities. Kernel Uprobe itself does not support this functionality, and kernel'sbpf_override_returnalso requires enabling the CONFIG_BPF_KPROBE_OVERRIDE option at compile time for security reasons, which is not enabled by default in mainstream Linux distributions.Hot Patching: As mentioned earlier, using the bpf_override_return helper mechanism, user-space eBPF can also replace or filter certain function calls, thus enabling hot patching capabilities.eBPF-based Nginx Module: bpftime can be used as an Nginx Module to implement extensions in Nginx through eBPF, such as dynamic routing, load balancing, caching, security policies, etc., in Nginx.Enhancing Fuse: There have been attempts to optimize Fuse using eBPF in the kernel. bpftime could also be used as part of a user-space filesystem, modifying the behavior of system calls in the corresponding user-space process through eBPF, enabling filesystem extensions such as dynamic routing, caching, security policies, etc., in user-space filesystems.
bpftime is currently an early-stage exploratory project. We are actively exploring more potential application scenarios, such as implementing eBPF-based network packet filtering in user space, optimizing packet forwarding performance for service meshes, bypassing the kernel's network protocol stack, and more. We look forward to more ideas and suggestions from everyone, or working together to implement these functions. In the future, we also hope that bpftime can offer better compatibility support for the kernel and, with the help of LLVM's JIT compiler, provide better performance optimization guidance, and a more convenient testing and debugging
Conclusion
bpftime opens up new possibilities for eBPF applications in user space and provides new options for extending user-space applications. It allows existing eBPF applications to run in non-privileged user space using the same libraries and toolchains, and offers tracing mechanisms like Uprobe and Syscall for user-space eBPF. Compared to kernel Uprobe, it significantly improves performance and does not require manual code instrumentation or process restarts. The runtime supports inter-process eBPF maps in user-space shared memory, and is also compatible with kernel eBPF maps, allowing seamless operation with the kernel eBPF infrastructure.
bpftime is now open source on GitHub, and everyone is welcome to try it out and provide feedback: https://github.com/eunomia-bpf/bpftime If you have any suggestions or questions, feel free to raise an issue on GitHub or contact us by email at mailto:[email protected].
References
- bpftime Git repo: https://github.com/eunomia-bpf/bpftime
- bpftime Linux Plumbers talk: https://lpc.events/event/17/contributions/1639/
- ubpf: https://github.com/iovisor/ubpf
- rbpf: https://github.com/qmonnet/rbpf
- Performance comparison of uprobe and kprobe: https://dl.acm.org/doi/10.1145/3603269.3604823
- Capturing Opening Files and Filter with Global Variables: https://eunomia.dev/tutorials/4-opensnoop/
- examples: https://github.com/eunomia-bpf/bpftime/tree/master/example
- sslsniff, based on the tool of the same name in bcc: https://github.com/eunomia-bpf/bpftime/tree/master/example/sslsniff
- bpf benchmark: https://github.com/eunomia-bpf/bpf-benchmark
- BPF-based error injection for the kernel: https://lwn.net/Articles/740146/
- FUSE BPF: A Stacked Filesystem Extension for FUSE: https://lwn.net/Articles/915717/
Continue exploring
Back to index
bpftime
High-performance userspace eBPF runtime and extension framework for production tracing, runtime extension, and low-overhead instrumentation.
Previous
bpftime
High-performance userspace eBPF runtime and extension framework for production tracing, runtime extension, and low-overhead instrumentation.
Next
Installation and Test
- Building and Test - Table of Contents - Use docker image - Install Dependencies - Build and install all things - Detailed things about building - build options - Build and install the complete runtime in release
- Last updated
- Feb 10, 2025
- First published
- Oct 6, 2023
- Contributors
- 云微, yunwei37, yunwei37
Was this page helpful?