Use cases
- Low-overhead tracing
- Custom runtime extension
- uprobe / syscall / USDT / XDP / GPU paths
- Production integration
Product / Runtime
A high-performance userspace eBPF runtime and extension framework for production extension, observability, and GPU-aware instrumentation.

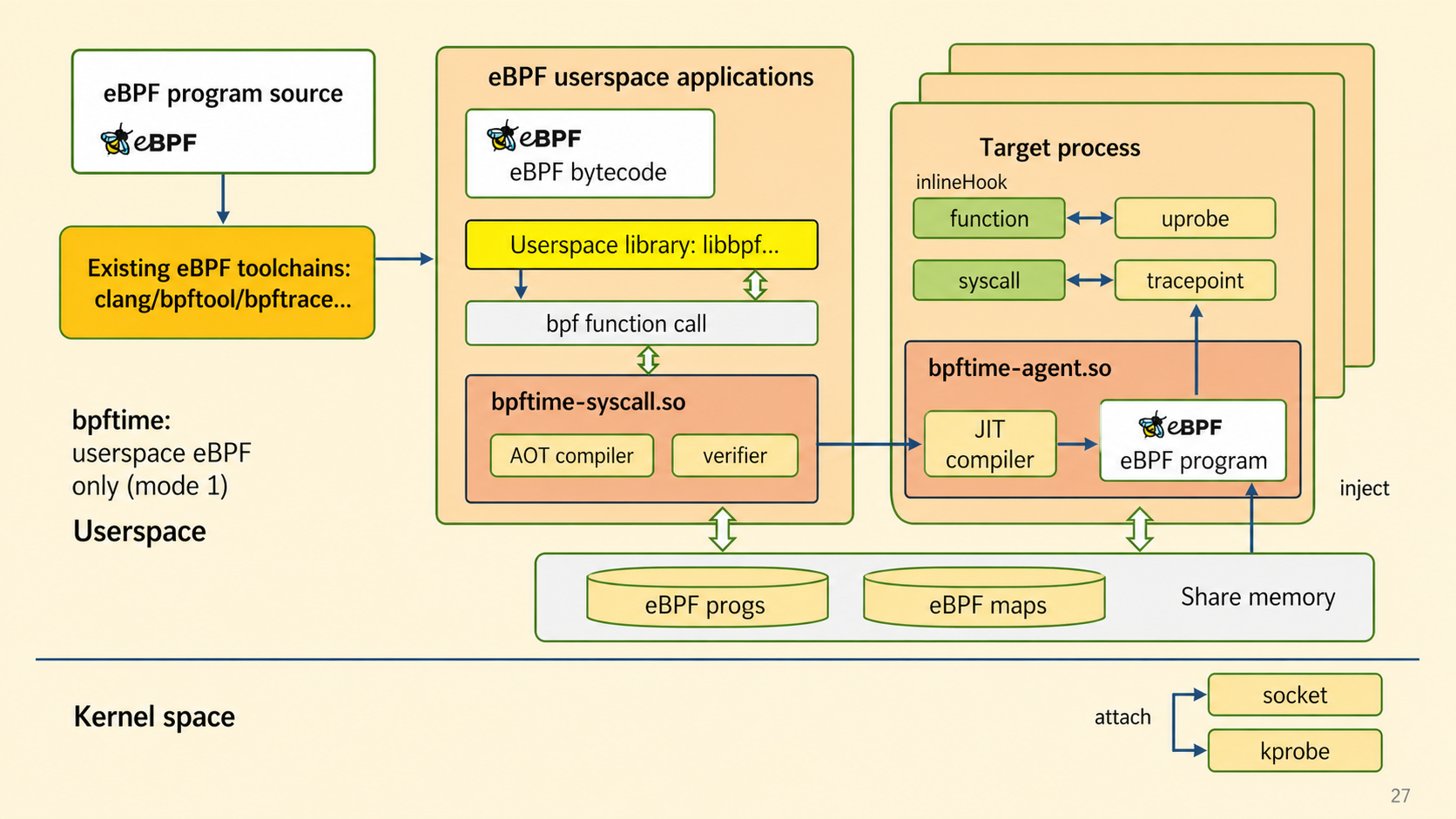
Support covers production integration, performance work, and custom runtime engineering around the open-source runtime.
Enterprise support
Integrate bpftime into existing tracing, networking, sandboxing, or runtime extension workflows.
Performance
Benchmark, profile, and tune uprobe, syscall, USDT, XDP, and GPU-related execution paths.
Custom runtime
Build attach paths, helpers, maps, policies, and deployment models for specific production systems.
Contact
Maintained by the eunomia-bpf open-source team, focused on systems engineering for eBPF, runtime extension, and AI agent infrastructure. Reach out directly for enterprise evaluation, POCs, and production integration.