Using ChatGPT to Write eBPF Programs and Trace Linux Systems with Natural Language
eBPF is a revolutionary technology that originated in the Linux kernel and allows sandboxed programs to run in the kernel of an operating system. It is used to securely and efficiently extend the functionality of the kernel without changing its source code or loading kernel modules. Today, eBPF is widely used in various scenarios: in modern data centers and cloud-native environments, it can provide high-performance network packet processing and load balancing; with very low resource overhead, it enables observability of various fine-grained metrics, helping application developers trace applications and gain insights for performance troubleshooting; it ensures secure execution of applications and container runtimes, and more. eBPF has become an increasingly popular technology that helps us to efficiently trace and analyze almost all applications in the kernel and user space.
However, developing eBPF programs or tracing various events generated by the kernel requires certain expertise. For developers unfamiliar with this technology, it can be challenging. In this case, the new ideas brought by our demo tool, GPTtrace, might help you solve this problem. It uses ChatGPT to write eBPF programs and trace the Linux kernel with natural language: https://github.com/eunomia-bpf/GPTtrace
If you are a developer who wants to trace and analyze more efficiently, similar solutions are definitely worth trying. The combination of ChatGPT and eBPF technology will play a more important role in future software development, debugging, and observability scenarios, and it may also bring a new interactive learning paradigm.
What Have We Tried?
GPTtrace uses ChatGPT technology to allow developers to write eBPF programs and trace the Linux kernel in natural language, without the need for prior expertise in this technology. It enables developers to locate and solve software issues more quickly and accurately. For example, to count Page Faults based on process names:
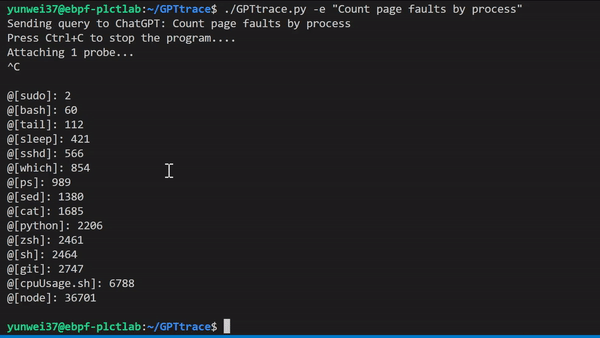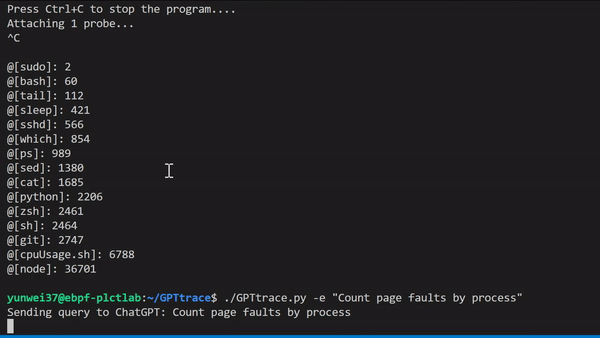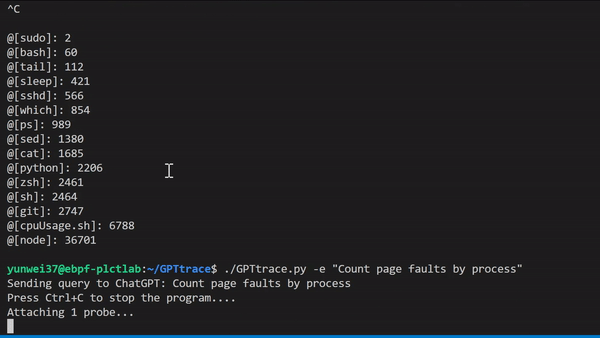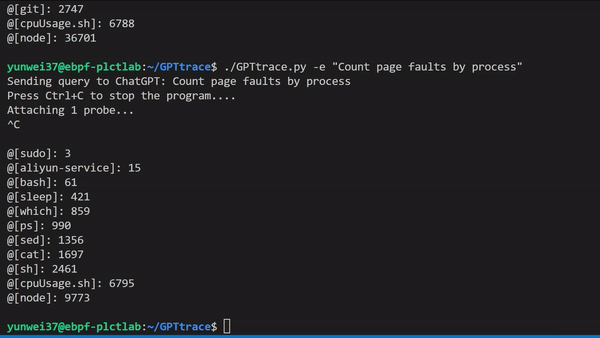
We also have a video demonstration and explanation which can be viewed here: https://www.bilibili.com/video/BV1oM411J7gp/
How Did We Achieve This?
Our current approach is to pretrain eBPF programs by having conversations with ChatGPT using various eBPF development materials, teaching ChatGPT how to write different eBPF programs or bpftrace DSL based on the context of the conversation (in fact, we did some similar practice in December and produced a tutorial document, but we didn't turn it into a tool: https://github.com/eunomia-bpf/bpf-developer-tutorial). Here's the rough breakdown:
- Pretrain eBPF programs by having conversations with ChatGPT using eBPF development materials to teach ChatGPT how to write different eBPF programs or bpftrace DSL.
- Call the ChatGPT API and parse the returned result to execute it as a command in the shell or write the eBPF program to a file for compilation and execution.
- If there are compilation and loading errors, return the corresponding error messages to ChatGPT to generate a new eBPF program or command.
We used the ChatGPT Python API and spent an afternoon implementing this little toy. It can accept natural language descriptions in various languages such as Chinese or English, for example, "trace open files in a process" or "show per-second syscall rates". The accuracy is not 100%, but out of ten attempts, roughly seven or eight should result in successful tracing. In case of errors, the tool can make corrections and adjustments on its own.
Further Improvements?
This toy project is intended to demonstrate the possibilities, and there should soon be better APIs like ChatGPT and more general training/execution frameworks available. Hopefully, it will serve as a catalyst for further development. Currently, it seems that there is still plenty of room for improvement:
- After enabling internet access, the tool could learn from the example programs in the bcc/bpftrace repository, which would greatly improve its effectiveness.
- Alternatively, the application itself could search Stack Overflow or similar platforms to query how to write eBPF programs, similar to the new search feature in Bing.
- Provide more high-quality documentation and tutorials, as the accuracy of the output is closely related to the quality of the tutorials and code examples.
- It is also possible to invoke other tools multiple times to execute commands, for example, using ChatGPT to output a command, querying the current kernel version and supported tracepoints using bpftrace, and returning the output (this is another conversation), followed by providing a program. This should yield much better results.Short-term, we hope to try building an interactive, informative kernel tracing tool and an eBPF program learning tutorial based on this tool. This will help users quickly understand the syntax and debug errors when writing eBPF programs, and adjust the quality of prompts and suggestions based on user feedback. We also aim to provide a structured tutorial for learning eBPF programming, starting from basic syntax and APIs, and gradually introducing common eBPF application scenarios and writing techniques based on the requirements of the final eBPF program the user wants to write.
In a sense, it might not even be just a language model. With the interactive mode of simple conversations and the ability to manipulate various tools and access the internet, it might serve as a huge and unprecedented knowledge base: connecting various professions, providing comprehensive summaries and thoughts that cannot be easily obtained through search engines based on natural language inputs.
In the era of information explosion, we can easily access massive amounts of information, but this also brings another problem, which is the dispersion and fragmentation of information, making it difficult to integrate this information into valuable knowledge. However, ChatGPT can integrate various information and knowledge through natural language interactions, even actively acquire knowledge and receive feedback (just like we did in GPTtrace), forming a huge knowledge base that provides comprehensive thoughts and answers to people.
This approach can connect various professions without being limited to specific fields or industries, and provide more accurate and comprehensive summaries based on natural language inputs. Additionally, since ChatGPT can manipulate various tools and access the internet, it can have a deeper understanding of various knowledge and information, and provide users with more comprehensive and in-depth answers.
This revolutionary change may already be on the eve of a transformation in human civilization. The way we acquire knowledge and thoughts will be disrupted, and the emergence of similar large-scale models will be an important driving force behind this transformation.
What does the future hold?
In fact, the performance of this model itself is not amazing, and there is still a lot of room for improvement. For someone like me who is not an AI professional researcher (a consumer of AI tools and models), compared to the traditional way of training deep learning models:
- Training models do not require organizing and cleaning datasets, only a few high-quality documents and tutorials are needed, in very small quantities, described in natural language; greatly reducing the preparation work for non-professionals.
- Training can be done intuitively and conveniently with just the conversation context, and anyone can easily understand (or try to analogize) how AI learns.
- It can adapt to many different tasks in various fields, as long as any task can be converted into a piece of text or command.
As Mr. Che Wanxiang from Harbin Institute of Technology mentioned in the Qingyuan Workshop, in the ChatGPT era, the dangers and opportunities for NLPers are as follows:
In the era of ChatGPT, to cope with current challenges, researchers in the field of natural language can learn from information retrieval researchers' experiences. Firstly, academia may no longer conduct systematic research, but mainly focus on relatively marginal research directions; secondly, experiments using data provided by industrial giants may not necessarily yield reliable conclusions, as there are doubts about the authenticity of data due to privacy concerns; conducting research by calling APIs provided by companies may lead to changes in conclusions once the model is adjusted.
When the threshold for using AI to solve specific problems becomes low enough, it becomes an enormous opportunity for AI to further popularize and solve problems in more specific scenarios. On the other hand, it may also be the support for AI's infrastructure: when the cost of generating content (such as code, text, algorithms, audio, and video) becomes cheaper, programmable and low-code platforms may become more scalable and reusable compared to the previous huge monolithic applications. For example, directly generating a FaaS interface from a description or interactive dialogue, directly generating a web front-end and deploying it, or using the code generated by ChatGPT as an observable collection and data processing program, deployed to a large-scale observability platform.
We are also exploring some compilation toolchains and runtimes that combine eBPF and Wasm, with the aim of achieving programmable extensions from kernel space to user space: https://github.com/eunomia-bpf/wasm-bpf
Some reference links
- ChatGPT: https://chat.openai.com/chat
- GPTtrace: https://github.com/eunomia-bpf/GPTtrace
- ChatGPT Python API: https://github.com/mmabrouk/chatgpt-wrapper
- eBPF Developer Tutorial Based on CO-RE (Write Once, Run Everywhere) libbpf: Learn eBPF step by step through 20 small tools (trying to teach ChatGPT to write eBPF programs): https://github.com/eunomia-bpf/bpf-developer-tutorial
- How ChatGPT-like tools achieve "strikes" | A summary of discussions on closed-door seminars on chatbots: https://mp.weixin.qq.com/s/fB9rguy26ej-alm7l_i8iQ
- eunomia-bpf Open Source Community: https://github.com/eunomia-bpf
Note: This article was written with the help of ChatGPT.
Continue exploring
Back to index
Blogs about eunomia-bpf community
- Modernizing eBPF for the Next Decade: Past, Present, and Future - Simplifying Kernel Programming: The LLM-Powered eBPF Tool - Expanding eBPF Compile Once, Run Everywhere(CO-RE) to Userspace Compatibility -
Previous
Simplifying eBPF Development: GitHub Templates and Codespaces for Online Compilation and Execution
Embarking on the eBPF journey can feel daunting, especially when confronted with setting up the perfect environment or making the ideal language choice.
Next
Writing eBPF Programs in C/C++ and libbpf in WebAssembly
eBPF (extended Berkeley Packet Filter) is a high-performance kernel virtual machine that runs in the kernel space and is used to collect system and network information.
- Last updated
- Aug 30, 2023
- First published
- Aug 15, 2023
- Contributors
- 云微, oluceps
Was this page helpful?