Can LLMs understand Linux kernel? A New AI-Powered Approach to Understanding Large Codebases
Ever tried diving into a massive codebase like the Linux kernel and felt like you were swimming in an ocean of code with no land in sight? Trust me, you're not alone. Understanding large, complex, and constantly evolving codebases is like trying to read a never-ending novel that's being written by thousands of authors simultaneously. It's overwhelming, to say the least.
See our arxiv and GitHub repository for more details!
The Struggle with Massive Codebases
Traditionally, developers have relied on methods like static code analysis, manual code reviews, and poring over documentation to make sense of big projects. While these methods can be helpful, they're often time-consuming, tedious, and frankly, not very effective when dealing with the sheer size and complexity of modern software systems.
You might be thinking, "Why not use AI to read and understand the entire codebase?" Well, here's the catch: even the most advanced Large Language Models (LLMs) have limitations. They can't process an entire massive codebase in one go due to context length restrictions. Techniques like Retrieval Augmented Generation (RAG) or fine-tuning models on specific datasets can help with specific functions or code snippets but fall short when it comes to capturing the broader picture of how a massive system evolves over time.
Why Can't We Just Use RAG or Fine-Tuning?
Great question! Let's break it down:
-
Retrieval Augmented Generation (RAG): This technique involves fetching relevant documents to help the AI generate responses. But with a codebase as vast as the Linux kernel, it's like trying to find all the needles in a haystack the size of a skyscraper. It's impractical to retrieve and process all the necessary documents to get a comprehensive understanding.
-
Fine-Tuning: Fine-tuning an AI model on a specific dataset helps it understand that data better. However, it requires substantial resources, and the model still can't process the entire context of a massive codebase simultaneously. Plus, codebases evolve rapidly, so the model would need constant retraining to stay up-to-date.
The Core Problem
Understanding not just the code but the evolution of a codebase—why certain decisions were made, how features have changed, and where potential issues lie—is incredibly challenging. The unstructured nature of development artifacts like commit messages, code reviews, and mailing list discussions adds another layer of complexity. These sources contain invaluable insights into the reasoning behind changes, but they're difficult to analyze systematically because they're, well, unstructured.
Enter Code-Survey
We're excited to introduce Code-Survey, a novel AI-powered methodology we've developed to tackle this exact problem. Instead of trying to cram an entire codebase into an AI model (which, trust us, doesn't work), Code-Survey takes a different approach.
So, What's the Big Idea?
Code-Survey leverages LLMs in a new way. We treat the AI as if it's a human participant in a survey. Think of it as conducting a massive questionnaire where the AI reads through unstructured data—like commit messages, code diffs, and emails—and answers specific, carefully designed questions. This method transforms messy, unstructured information into clean, structured datasets that we can actually analyze.
Why This Approach Works
By framing the problem as a survey, we're playing to the strengths of AI language models. They're great at understanding and generating human-like text but struggle with processing enormous amounts of code all at once. This method allows us to extract meaningful insights without overloading the AI or losing important context. It's like having an army of junior developers summarizing and categorizing information for you, but faster and without the coffee breaks!
Understanding Codebases Before Code-Survey
Before Code-Survey, making sense of large codebases was a daunting task. Developers would manually sift through code, comb through commit histories, and read endless documentation and mailing list archives. This was not only time-consuming but also prone to human error. Answering high-level questions like "Why was this feature added?" or "How has this component evolved over time?" was nearly impossible without dedicating significant resources.
Applying Code-Survey to the Linux eBPF Subsystem
To put Code-Survey to the test, we applied it to the Linux kernel's Extended Berkeley Packet Filter (eBPF) subsystem. For those unfamiliar, eBPF is like the Swiss Army knife of the Linux kernel, enabling advanced networking, observability, and security functionalities without changing kernel source code.
Why eBPF?
- Complexity: eBPF has evolved rapidly, with countless features added over the years, making it a perfect candidate to showcase Code-Survey's capabilities.
- Unstructured Data: There's a wealth of information hidden in commits, code reviews, and mailing lists that hasn't been systematically analyzed.
- Impact: Understanding eBPF's evolution can lead to improvements in performance, security, and reliability for the countless systems that rely on it.
What We Discovered
Using Code-Survey, we analyzed over 16,000 commits and 150,000 emails related to eBPF development. Here are some of the insights we gained:
-
Feature Evolution: We mapped out how features like
bpf_link(which provides a new abstraction for attaching programs to events) have developed over time. Surprisingly, despite being in the codebase for years, some features haven't received much attention outside of kernel developer circles. -
Bug Patterns: We identified which components and files in the Linux kernel have the highest frequency of bugs. Interestingly, while much focus has been on the verifier and JIT compiler, a significant number of bugs stem from eBPF's interactions with other kernel subsystems.
-
Development Trends: We observed shifts in development focus over the years, such as a move from adding new features to improving stability and performance.
-
Feature Interdependencies: We uncovered dependencies between features and components, providing insights into how new feature introductions impact the stability and performance of existing kernel components.
Core Concepts: The Survey Methodology
The central principle behind Code-Survey is treating LLMs as human participants, acknowledging that software development is also a social activity. By carefully designing surveys, Code-Survey transforms unstructured data—like commits and emails—into organized, structured, and analyzable datasets.
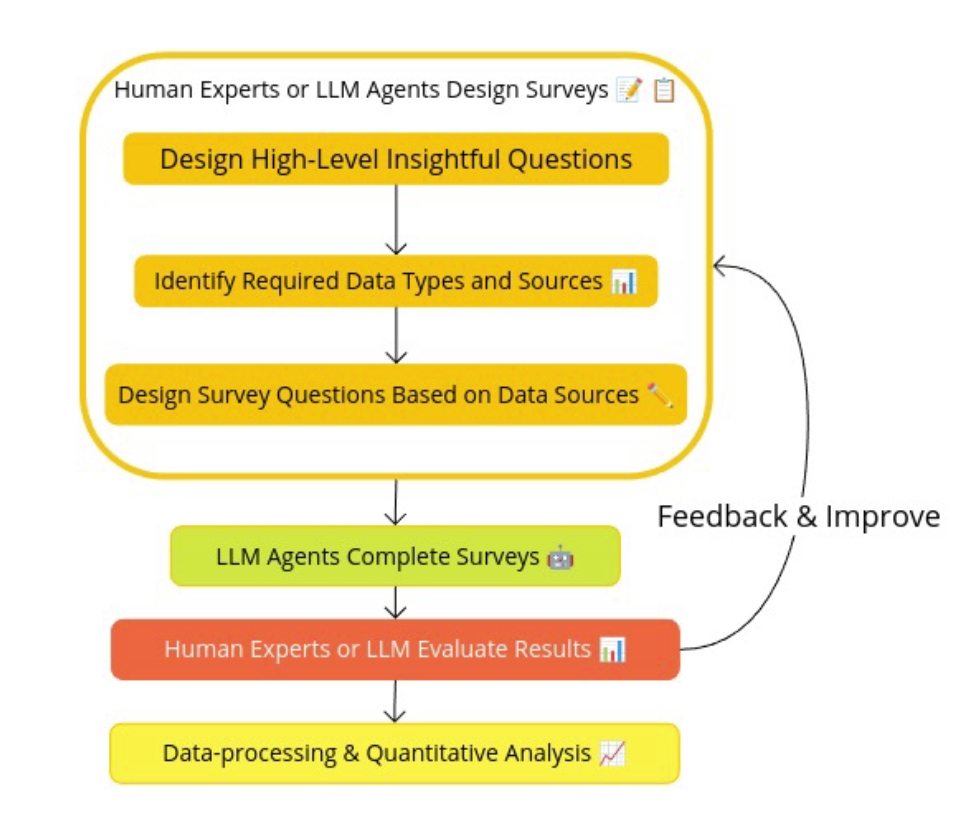
Here's how it works:
-
Survey Design: We (or the AI) design surveys with specific questions targeting the information we want to extract. For example:
- "What is the main purpose of this commit?"
- "Which eBPF components are affected?"
- "Is this a bug fix, a new feature, or a performance optimization?"
-
AI Processing: The AI reads through the unstructured data and answers the survey questions, effectively structuring the data.
-
Validation: Human experts review samples of the AI's responses to ensure accuracy. If there are issues, we refine the survey or the AI's approach.
-
Analysis: With structured data in hand, we perform quantitative analyses to uncover trends, patterns, and areas needing attention.
Why This Matters
This approach allows us to answer questions that were previously nearly impossible to tackle, such as:
- "How do new feature introductions impact the stability of existing components?"
- "Are there identifiable phases in the lifecycle of a feature?"
- "Which components have the highest bug frequency?"
Benefits of Code-Survey
-
Scalable Analysis: We can process thousands of commits and discussions quickly, something unfeasible with manual methods.
-
Deep Insights: By structuring the data, we can perform analyses that weren't possible before, uncovering hidden patterns and trends.
-
Versatility: The methodology is flexible and can be applied to other large codebases beyond the Linux kernel.
Best Practices We've Learned
-
Careful Survey Design: The quality of insights depends on well-designed questions. They should be clear, specific, and aligned with the AI's capabilities.
-
Use Predefined Categories: This helps maintain consistency in the AI's responses and reduces ambiguity.
-
Allow for Uncertainty: Letting the AI say "I'm not sure" prevents inaccurate information when the data is insufficient.
-
Iterative Refinement: Continuously refining survey questions and validating responses improves accuracy over time.
Limitations to Keep in Mind
-
Data Quality Matters: Incomplete or unclear commit messages can affect the AI's ability to provide accurate answers.
-
AI Isn't Perfect: Sometimes, the AI might misinterpret data or generate plausible but incorrect information.
-
Human Oversight Needed: Experts are essential for designing surveys and validating results, ensuring the AI's outputs are reliable.
What's Next for Code-Survey?
We're excited about the potential of applying Code-Survey to other massive projects like Kubernetes, Apache, or even proprietary codebases. We also plan to incorporate additional data sources, such as actual code changes, execution traces, and performance metrics, to gain even deeper insights.
Join Us on This Journey
We believe Code-Survey represents a significant leap forward in how we understand and maintain large codebases. By combining the power of AI with thoughtful survey design, we're unlocking insights that were previously hidden in plain sight.
Want to Get Involved?
Code-Survey is open-source! Check out our GitHub repository to explore the code, access the datasets, and contribute to the project. Whether you're a developer, researcher, or just curious, we welcome your feedback and collaboration.
For updates on Code-Survey and our other projects, follow us on GitHub and join the conversation. Together, we can make navigating massive codebases less daunting and more efficient.
References:
- eBPF Intro: What is eBPF?
- eBPF Tutorial: bpf-developer-tutorial
- Code-Survey GitHub Repository: github.com/eunomia-bpf/code-survey
Feel free to reach out with any questions or comments. Let's revolutionize how we understand and work with large codebases together!
Continue exploring
Back to index
Blogs about eunomia-bpf community
- Modernizing eBPF for the Next Decade: Past, Present, and Future - Simplifying Kernel Programming: The LLM-Powered eBPF Tool - Expanding eBPF Compile Once, Run Everywhere(CO-RE) to Userspace Compatibility -
Previous
bpftime: Extending eBPF from Kernel to User Space
eBPF is a revolutionary technology that originated in the Linux kernel, enabling sandboxed programs to run within the operating system's kernel.
Next
eunomia-bpf: Looking forward to 2023, let eBPF sprout wings with Wasm
Looking back at 2022, two technologies have received a lot of attention: eBPF and WebAssembly.
- Last updated
- Oct 13, 2024
- First published
- Oct 11, 2024
- Contributors
- 云微
Was this page helpful?