eBPF入门开发实践教程十三:统计 TCP 连接延时,并使用 libbpf 在用户态处理数据
eBPF (Extended Berkeley Packet Filter) 是一项强大的网络和性能分析工具,被应用在 Linux 内核上。eBPF 允许开发者动态加载、更新和运行用户定义的代码,而无需重启内核或更改内核源代码。
本文是 eBPF 入门开发实践教程的第十三篇,主要介绍如何使用 eBPF 统计 TCP 连接延时,并使用 libbpf 在用户态处理数据。
背景
在进行后端开发时,不论使用何种编程语言,我们都常常需要调用 MySQL、Redis 等数据库,或执行一些 RPC 远程调用,或者调用其他的 RESTful API。这些调用的底层,通常都是基于 TCP 协议进行的。原因是 TCP 协议具有可靠连接、错误重传、拥塞控制等优点,因此在网络传输层协议中,TCP 的应用广泛程度超过了 UDP。然而,TCP 也有一些缺点,如建立连接的延时较长。因此,也出现了一些替代方案,例如 QUIC(Quick UDP Internet Connections,快速 UDP 网络连接)。
分析 TCP 连接延时对网络性能分析、优化以及故障排查都非常有用。
tcpconnlat 工具概述
tcpconnlat 这个工具能够跟踪内核中执行活动 TCP 连接的函数(如通过 connect() 系统调用),并测量并显示连接延时,即从发送 SYN 到收到响应包的时间。
TCP 连接原理
TCP 连接的建立过程,常被称为“三次握手”(Three-way Handshake)。以下是整个过程的步骤:
- 客户端向服务器发送 SYN 包:客户端通过
connect()系统调用发出 SYN。这涉及到本地的系统调用以及软中断的 CPU 时间开销。 - SYN 包传送到服务器:这是一次网络传输,涉及到的时间取决于网络延迟。
- 服务器处理 SYN 包:服务器内核通过软中断接收包,然后将其放入半连接队列,并发送 SYN/ACK 响应。这主要涉及 CPU 时间开销。
- SYN/ACK 包传送到客户端:这是另一次网络传输。
- 客户端处理 SYN/ACK:客户端内核接收并处理 SYN/ACK 包,然后发送 ACK。这主要涉及软中断处理开销。
- ACK 包传送到服务器:这是第三次网络传输。
- 服务器接收 ACK:服务器内核接收并处理 ACK,然后将对应的连接从半连接队列移动到全连接队列。这涉及到一次软中断的 CPU 开销。
- 唤醒服务器端用户进程:被
accept()系统调用阻塞的用户进程被唤醒,然后从全连接队列中取出来已经建立好的连接。这涉及一次上下文切换的CPU开销。
完整的流程图如下所示:
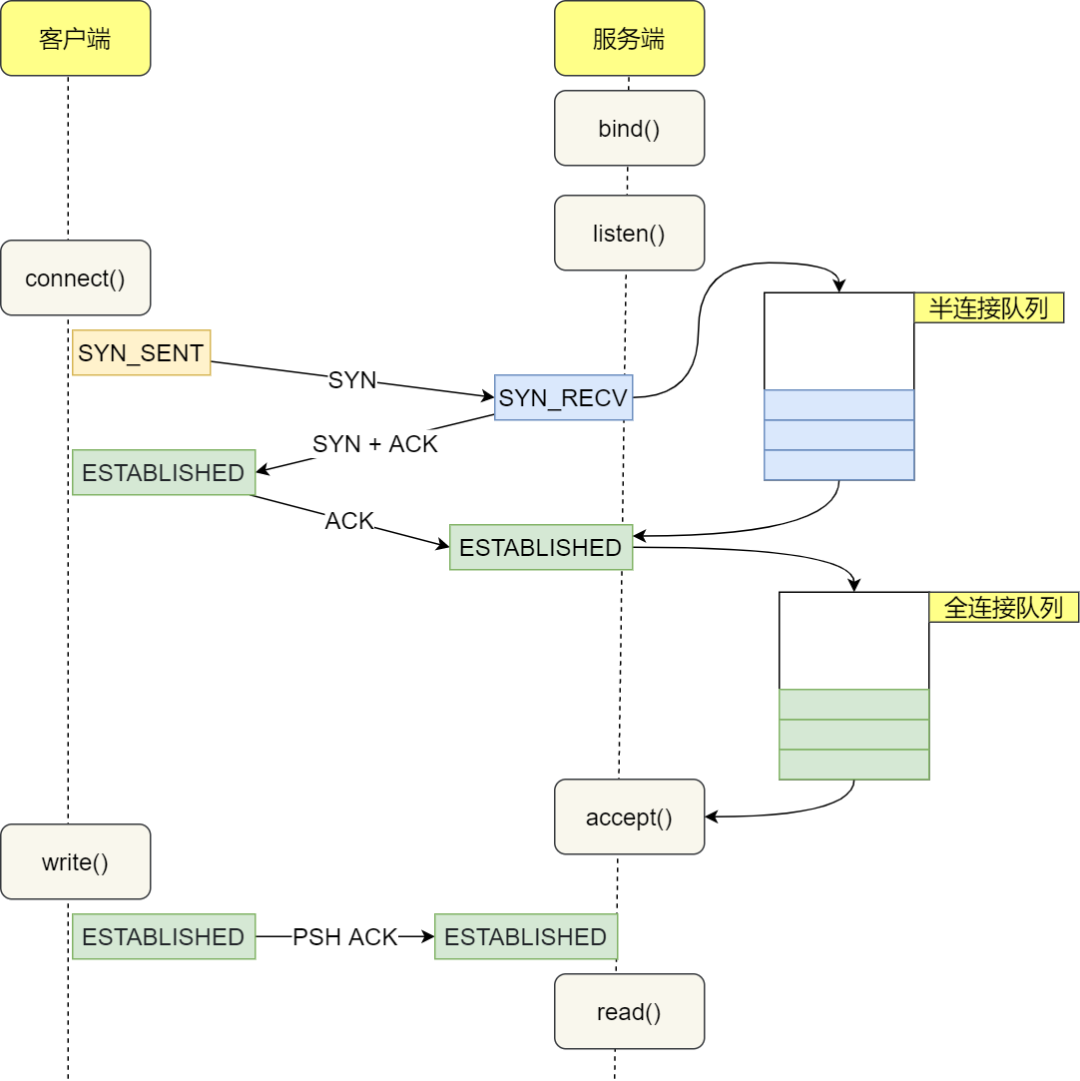
在客户端视角,在正常情况下一次TCP连接总的耗时也就就大约是一次网络RTT的耗时。但在某些情况下,可能会导致连接时的网络传输耗时上涨、CPU处理开销增加、甚至是连接失败。这种时候在发现延时过长之后,就可以结合其他信息进行分析。
tcpconnlat 的 eBPF 实现
为了理解 TCP 的连接建立过程,我们需要理解 Linux 内核在处理 TCP 连接时所使用的两个队列:
- 半连接队列(SYN 队列):存储那些正在进行三次握手操作的 TCP 连接,服务器收到 SYN 包后,会将该连接信息存储在此队列中。
- 全连接队列(Accept 队列):存储已经完成三次握手,等待应用程序调用
accept()函数的 TCP 连接。服务器在收到 ACK 包后,会创建一个新的连接并将其添加到此队列。
理解了这两个队列的用途,我们就可以开始探究 tcpconnlat 的具体实现。tcpconnlat 的实现可以分为内核态和用户态两个部分,其中包括了几个主要的跟踪点:tcp_v4_connect, tcp_v6_connect 和 tcp_rcv_state_process。
这些跟踪点主要位于内核中的 TCP/IP 网络栈。当执行相关的系统调用或内核函数时,这些跟踪点会被激活,从而触发 eBPF 程序的执行。这使我们能够捕获和测量 TCP 连接建立的整个过程。
让我们先来看一下这些挂载点的源代码:
SEC("kprobe/tcp_v4_connect")
int BPF_KPROBE(tcp_v4_connect, struct sock *sk)
{
return trace_connect(sk);
}
SEC("kprobe/tcp_v6_connect")
int BPF_KPROBE(tcp_v6_connect, struct sock *sk)
{
return trace_connect(sk);
}
SEC("kprobe/tcp_rcv_state_process")
int BPF_KPROBE(tcp_rcv_state_process, struct sock *sk)
{
return handle_tcp_rcv_state_process(ctx, sk);
}
这段代码展示了三个内核探针(kprobe)的定义。tcp_v4_connect 和 tcp_v6_connect 在对应的 IPv4 和 IPv6 连接被初始化时被触发,调用 trace_connect() 函数,而 tcp_rcv_state_process 在内核处理 TCP 连接状态变化时被触发,调用 handle_tcp_rcv_state_process() 函数。
接下来的部分将分为两大块:一部分是对这些挂载点内核态部分的分析,我们将解读内核源代码来详细说明这些函数如何工作;另一部分是用户态的分析,将关注 eBPF 程序如何收集这些挂载点的数据,以及如何与用户态程序进行交互。
tcp_v4_connect 函数解析
tcp_v4_connect函数是Linux内核处理TCP的IPv4连接请求的主要方式。当用户态程序通过socket系统调用创建了一个套接字后,接着通过connect系统调用尝试连接到远程服务器,此时就会触发tcp_v4_connect函数。
/* This will initiate an outgoing connection. */
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
struct inet_timewait_death_row *tcp_death_row;
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
struct ip_options_rcu *inet_opt;
struct net *net = sock_net(sk);
__be16 orig_sport, orig_dport;
__be32 daddr, nexthop;
struct flowi4 *fl4;
struct rtable *rt;
int err;
if (addr_len < sizeof(struct sockaddr_in))
return -EINVAL;
if (usin->sin_family != AF_INET)
return -EAFNOSUPPORT;
nexthop = daddr = usin->sin_addr.s_addr;
inet_opt = rcu_dereference_protected(inet->inet_opt,
lockdep_sock_is_held(sk));
if (inet_opt && inet_opt->opt.srr) {
if (!daddr)
return -EINVAL;
nexthop = inet_opt->opt.faddr;
}
orig_sport = inet->inet_sport;
orig_dport = usin->sin_port;
fl4 = &inet->cork.fl.u.ip4;
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
sk->sk_bound_dev_if, IPPROTO_TCP, orig_sport,
orig_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
if (err == -ENETUNREACH)
IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES);
return err;
}
if (rt->rt_flags & (RTCF_MULTICAST | RTCF_BROADCAST)) {
ip_rt_put(rt);
return -ENETUNREACH;
}
if (!inet_opt || !inet_opt->opt.srr)
daddr = fl4->daddr;
tcp_death_row = &sock_net(sk)->ipv4.tcp_death_row;
if (!inet->inet_saddr) {
err = inet_bhash2_update_saddr(sk, &fl4->saddr, AF_INET);
if (err) {
ip_rt_put(rt);
return err;
}
} else {
sk_rcv_saddr_set(sk, inet->inet_saddr);
}
if (tp->rx_opt.ts_recent_stamp && inet->inet_daddr != daddr) {
/* Reset inherited state */
tp->rx_opt.ts_recent = 0;
tp->rx_opt.ts_recent_stamp = 0;
if (likely(!tp->repair))
WRITE_ONCE(tp->write_seq, 0);
}
inet->inet_dport = usin->sin_port;
sk_daddr_set(sk, daddr);
inet_csk(sk)->icsk_ext_hdr_len = 0;
if (inet_opt)
inet_csk(sk)->icsk_ext_hdr_len = inet_opt->opt.optlen;
tp->rx_opt.mss_clamp = TCP_MSS_DEFAULT;
/* Socket identity is still unknown (sport may be zero).
* However we set state to SYN-SENT and not releasing socket
* lock select source port, enter ourselves into the hash tables and
* complete initialization after this.
*/
tcp_set_state(sk, TCP_SYN_SENT);
err = inet_hash_connect(tcp_death_row, sk);
if (err)
goto failure;
sk_set_txhash(sk);
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
if (IS_ERR(rt)) {
err = PTR_ERR(rt);
rt = NULL;
goto failure;
}
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
rt = NULL;
if (likely(!tp->repair)) {
if (!tp->write_seq)
WRITE_ONCE(tp->write_seq,
secure_tcp_seq(inet->inet_saddr,
inet->inet_daddr,
inet->inet_sport,
usin->sin_port));
tp->tsoffset = secure_tcp_ts_off(net, inet->inet_saddr,
inet->inet_daddr);
}
inet->inet_id = get_random_u16();
if (tcp_fastopen_defer_connect(sk, &err))
return err;
if (err)
goto failure;
err = tcp_connect(sk);
if (err)
goto failure;
return 0;
failure:
/*
* This unhashes the socket and releases the local port,
* if necessary.
*/
tcp_set_state(sk, TCP_CLOSE);
inet_bhash2_reset_saddr(sk);
ip_rt_put(rt);
sk->sk_route_caps = 0;
inet->inet_dport = 0;
return err;
}
EXPORT_SYMBOL(tcp_v4_connect);
参考链接:https://elixir.bootlin.com/linux/latest/source/net/ipv4/tcp_ipv4.c#L340
接下来,我们一步步分析这个函数:
首先,这个函数接收三个参数:一个套接字指针sk,一个指向套接字地址结构的指针uaddr和地址的长度addr_len。
函数一开始就进行了参数检查,确认地址长度正确,而且地址的协议族必须是IPv4。不满足这些条件会导致函数返回错误。
接下来,函数获取目标地址,如果设置了源路由选项(这是一个高级的IP特性,通常不会被使用),那么它还会获取源路由的下一跳地址。
nexthop = daddr = usin->sin_addr.s_addr;
inet_opt = rcu_dereference_protected(inet->inet_opt,
lockdep_sock_is_held(sk));
if (inet_opt && inet_opt->opt.srr) {
if (!daddr)
return -EINVAL;
nexthop = inet_opt->opt.faddr;
}
然后,使用这些信息来寻找一个路由到目标地址的路由项。如果不能找到路由项或者路由项指向一个多播或广播地址,函数返回错误。
接下来,它更新了源地址,处理了一些TCP时间戳选项的状态,并设置了目标端口和地址。之后,它更新了一些其他的套接字和TCP选项,并设置了连接状态为SYN-SENT。
然后,这个函数使用inet_hash_connect函数尝试将套接字添加到已连接的套接字的散列表中。如果这步失败,它会恢复套接字的状态并返回错误。
如果前面的步骤都成功了,接着,使用新的源和目标端口来更新路由项。如果这步失败,它会清理资源并返回错误。
接下来,它提交目标信息到套接字,并为之后的分段偏移选择一个安全的随机值。
然后,函数尝试使用TCP Fast Open(TFO)进行连接,如果不能使用TFO或者TFO尝试失败,它会使用普通的TCP三次握手进行连接。
最后,如果上面的步骤都成功了,函数返回成功,否则,它会清理所有资源并返回错误。
总的来说,tcp_v4_connect函数是一个处理TCP连接请求的复杂函数,它处理了很多情况,包括参数检查、路由查找、源地址选择、源路由、TCP选项处理、TCP Fast Open,等等。它的主要目标是尽可能安全和有效地建立TCP连接。
内核态代码
// SPDX-License-Identifier: GPL-2.0
// Copyright (c) 2020 Wenbo Zhang
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_core_read.h>
#include <bpf/bpf_tracing.h>
#include "tcpconnlat.h"
#define AF_INET 2
#define AF_INET6 10
const volatile __u64 targ_min_us = 0;
const volatile pid_t targ_tgid = 0;
struct piddata {
char comm[TASK_COMM_LEN];
u64 ts;
u32 tgid;
};
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 4096);
__type(key, struct sock *);
__type(value, struct piddata);
} start SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
} events SEC(".maps");
static int trace_connect(struct sock *sk)
{
u32 tgid = bpf_get_current_pid_tgid() >> 32;
struct piddata piddata = {};
if (targ_tgid && targ_tgid != tgid)
return 0;
bpf_get_current_comm(&piddata.comm, sizeof(piddata.comm));
piddata.ts = bpf_ktime_get_ns();
piddata.tgid = tgid;
bpf_map_update_elem(&start, &sk, &piddata, 0);
return 0;
}
static int handle_tcp_rcv_state_process(void *ctx, struct sock *sk)
{
struct piddata *piddatap;
struct event event = {};
s64 delta;
u64 ts;
if (BPF_CORE_READ(sk, __sk_common.skc_state) != TCP_SYN_SENT)
return 0;
piddatap = bpf_map_lookup_elem(&start, &sk);
if (!piddatap)
return 0;
ts = bpf_ktime_get_ns();
delta = (s64)(ts - piddatap->ts);
if (delta < 0)
goto cleanup;
event.delta_us = delta / 1000U;
if (targ_min_us && event.delta_us < targ_min_us)
goto cleanup;
__builtin_memcpy(&event.comm, piddatap->comm,
sizeof(event.comm));
event.ts_us = ts / 1000;
event.tgid = piddatap->tgid;
event.lport = BPF_CORE_READ(sk, __sk_common.skc_num);
event.dport = BPF_CORE_READ(sk, __sk_common.skc_dport);
event.af = BPF_CORE_READ(sk, __sk_common.skc_family);
if (event.af == AF_INET) {
event.saddr_v4 = BPF_CORE_READ(sk, __sk_common.skc_rcv_saddr);
event.daddr_v4 = BPF_CORE_READ(sk, __sk_common.skc_daddr);
} else {
BPF_CORE_READ_INTO(&event.saddr_v6, sk,
__sk_common.skc_v6_rcv_saddr.in6_u.u6_addr32);
BPF_CORE_READ_INTO(&event.daddr_v6, sk,
__sk_common.skc_v6_daddr.in6_u.u6_addr32);
}
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU,
&event, sizeof(event));
cleanup:
bpf_map_delete_elem(&start, &sk);
return 0;
}
SEC("kprobe/tcp_v4_connect")
int BPF_KPROBE(tcp_v4_connect, struct sock *sk)
{
return trace_connect(sk);
}
SEC("kprobe/tcp_v6_connect")
int BPF_KPROBE(tcp_v6_connect, struct sock *sk)
{
return trace_connect(sk);
}
SEC("kprobe/tcp_rcv_state_process")
int BPF_KPROBE(tcp_rcv_state_process, struct sock *sk)
{
return handle_tcp_rcv_state_process(ctx, sk);
}
SEC("fentry/tcp_v4_connect")
int BPF_PROG(fentry_tcp_v4_connect, struct sock *sk)
{
return trace_connect(sk);
}
SEC("fentry/tcp_v6_connect")
int BPF_PROG(fentry_tcp_v6_connect, struct sock *sk)
{
return trace_connect(sk);
}
SEC("fentry/tcp_rcv_state_process")
int BPF_PROG(fentry_tcp_rcv_state_process, struct sock *sk)
{
return handle_tcp_rcv_state_process(ctx, sk);
}
char LICENSE[] SEC("license") = "GPL";
这个eBPF(Extended Berkeley Packet Filter)程序主要用来监控并收集TCP连接的建立时间,即从发起TCP连接请求(connect系统调用)到连接建立完成(SYN-ACK握手过程完成)的时间间隔。这对于监测网络延迟、服务性能分析等方面非常有用。
首先,定义了两个eBPF maps:start和events。start是一个哈希表,用于存储发起连接请求的进程信息和时间戳,而events是一个PERF_EVENT_ARRAY类型的map,用于将事件数据传输到用户态。
struct {
__uint(type, BPF_MAP_TYPE_HASH);
__uint(max_entries, 4096);
__type(key, struct sock *);
__type(value, struct piddata);
} start SEC(".maps");
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(u32));
__uint(value_size, sizeof(u32));
} events SEC(".maps");
在tcp_v4_connect和tcp_v6_connect的kprobe处理函数trace_connect中,会记录下发起连接请求的进程信息(进程名、进程ID和当前时间戳),并以socket结构作为key,存储到start这个map中。
static int trace_connect(struct sock *sk)
{
u32 tgid = bpf_get_current_pid_tgid() >> 32;
struct piddata piddata = {};
if (targ_tgid && targ_tgid != tgid)
return 0;
bpf_get_current_comm(&piddata.comm, sizeof(piddata.comm));
piddata.ts = bpf_ktime_get_ns();
piddata.tgid = tgid;
bpf_map_update_elem(&start, &sk, &piddata, 0);
return 0;
}
当TCP状态机处理到SYN-ACK包,即连接建立的时候,会触发tcp_rcv_state_process的kprobe处理函数handle_tcp_rcv_state_process。在这个函数中,首先检查socket的状态是否为SYN-SENT,如果是,会从start这个map中查找socket对应的进程信息。然后计算出从发起连接到现在的时间间隔,将该时间间隔,进程信息,以及TCP连接的详细信息(源端口,目标端口,源IP,目标IP等)作为event,通过bpf_perf_event_output函数发送到用户态。
static int handle_tcp_rcv_state_process(void *ctx, struct sock *sk)
{
struct piddata *piddatap;
struct event event = {};
s64 delta;
u64 ts;
if (BPF_CORE_READ(sk, __sk_common.skc_state) != TCP_SYN_SENT)
return 0;
piddatap = bpf_map_lookup_elem(&start, &sk);
if (!piddatap)
return 0;
ts = bpf_ktime_get_ns();
delta = (s64)(ts - piddatap->ts);
if (delta < 0)
goto cleanup;
event.delta_us = delta / 1000U;
if (targ_min_us && event.delta_us < targ_min_us)
goto
cleanup;
__builtin_memcpy(&event.comm, piddatap->comm,
sizeof(event.comm));
event.ts_us = ts / 1000;
event.tgid = piddatap->tgid;
event.lport = BPF_CORE_READ(sk, __sk_common.skc_num);
event.dport = BPF_CORE_READ(sk, __sk_common.skc_dport);
event.af = BPF_CORE_READ(sk, __sk_common.skc_family);
if (event.af == AF_INET) {
event.saddr_v4 = BPF_CORE_READ(sk, __sk_common.skc_rcv_saddr);
event.daddr_v4 = BPF_CORE_READ(sk, __sk_common.skc_daddr);
} else {
BPF_CORE_READ_INTO(&event.saddr_v6, sk,
__sk_common.skc_v6_rcv_saddr.in6_u.u6_addr32);
BPF_CORE_READ_INTO(&event.daddr_v6, sk,
__sk_common.skc_v6_daddr.in6_u.u6_addr32);
}
bpf_perf_event_output(ctx, &events, BPF_F_CURRENT_CPU,
&event, sizeof(event));
cleanup:
bpf_map_delete_elem(&start, &sk);
return 0;
}
理解这个程序的关键在于理解Linux内核的网络栈处理流程,以及eBPF程序的运行模式。Linux内核网络栈对TCP连接建立的处理过程是,首先调用tcp_v4_connect或tcp_v6_connect函数(根据IP版本不同)发起TCP连接,然后在收到SYN-ACK包时,通过tcp_rcv_state_process函数来处理。eBPF程序通过在这两个关键函数上设置kprobe,可以在关键时刻得到通知并执行相应的处理代码。
一些关键概念说明:
- kprobe:Kernel Probe,是Linux内核中用于动态追踪内核行为的机制。可以在内核函数的入口和退出处设置断点,当断点被触发时,会执行与kprobe关联的eBPF程序。
- map:是eBPF程序中的一种数据结构,用于在内核态和用户态之间共享数据。
- socket:在Linux网络编程中,socket是一个抽象概念,表示一个网络连接的端点。内核中的
struct sock结构就是对socket的实现。
用户态数据处理
用户态数据处理是使用perf_buffer__poll来接收并处理从内核发送到用户态的eBPF事件。perf_buffer__poll是libbpf库提供的一个便捷函数,用于轮询perf event buffer并处理接收到的数据。
首先,让我们详细看一下主轮询循环:
/* main: poll */
while (!exiting) {
err = perf_buffer__poll(pb, PERF_POLL_TIMEOUT_MS);
if (err < 0 && err != -EINTR) {
fprintf(stderr, "error polling perf buffer: %s\n", strerror(-err));
goto cleanup;
}
/* reset err to return 0 if exiting */
err = 0;
}
这段代码使用一个while循环来反复轮询perf event buffer。如果轮询出错(例如由于信号中断),会打印出错误消息。这个轮询过程会一直持续,直到收到一个退出标志exiting。
接下来,让我们来看看handle_event函数,这个函数将处理从内核发送到用户态的每一个eBPF事件:
void handle_event(void* ctx, int cpu, void* data, __u32 data_sz) {
const struct event* e = data;
char src[INET6_ADDRSTRLEN];
char dst[INET6_ADDRSTRLEN];
union {
struct in_addr x4;
struct in6_addr x6;
} s, d;
static __u64 start_ts;
if (env.timestamp) {
if (start_ts == 0)
start_ts = e->ts_us;
printf("%-9.3f ", (e->ts_us - start_ts) / 1000000.0);
}
if (e->af == AF_INET) {
s.x4.s_addr = e->saddr_v4;
d.x4.s_addr = e->daddr_v4;
} else if (e->af == AF_INET6) {
memcpy(&s.x6.s6_addr, e->saddr_v6, sizeof(s.x6.s6_addr));
memcpy(&d.x6.s6_addr, e->daddr_v6, sizeof(d.x6.s6_addr));
} else {
fprintf(stderr, "broken event: event->af=%d", e->af);
return;
}
if (env.lport) {
printf("%-6d %-12.12s %-2d %-16s %-6d %-16s %-5d %.2f\n", e->tgid,
e->comm, e->af == AF_INET ? 4 : 6,
inet_ntop(e->af, &s, src, sizeof(src)), e->lport,
inet_ntop(e->af, &d, dst, sizeof(dst)), ntohs(e->dport),
e->delta_us / 1000.0);
} else {
printf("%-6d %-12.12s %-2d %-16s %-16s %-5d %.2f\n", e->tgid, e->comm,
e->af == AF_INET ? 4 : 6, inet_ntop(e->af, &s, src, sizeof(src)),
inet_ntop(e->af, &d, dst, sizeof(dst)), ntohs(e->dport),
e->delta_us / 1000.0);
}
}
handle_event函数的参数包括了CPU编号、指向数据的指针以及数据的大小。数据是一个event结构体,包含了之前在内核态计算得到的TCP连接的信息。
首先,它将接收到的事件的时间戳和起始时间戳(如果存在)进行对比,计算出事件的相对时间,并打印出来。接着,根据IP地址的类型(IPv4或IPv6),将源地址和目标地址从网络字节序转换为主机字节序。
最后,根据用户是否选择了显示本地端口,将进程ID、进程名称、IP版本、源IP地址、本地端口(如果有)、目标IP地址、目标端口以及连接建立时间打印出来。这个连接建立时间是我们在内核态eBPF程序中计算并发送到用户态的。
编译运行
$ make
...
BPF .output/tcpconnlat.bpf.o
GEN-SKEL .output/tcpconnlat.skel.h
CC .output/tcpconnlat.o
BINARY tcpconnlat
$ sudo ./tcpconnlat
PID COMM IP SADDR DADDR DPORT LAT(ms)
222564 wget 4 192.168.88.15 110.242.68.3 80 25.29
222684 wget 4 192.168.88.15 167.179.101.42 443 246.76
222726 ssh 4 192.168.88.15 167.179.101.42 22 241.17
222774 ssh 4 192.168.88.15 1.15.149.151 22 25.31
源代码:https://github.com/eunomia-bpf/bpf-developer-tutorial/tree/main/src/13-tcpconnlat 关于如何安装依赖,请参考:https://eunomia.dev/tutorials/11-bootstrap/
参考资料:
总结
通过本篇 eBPF 入门实践教程,我们学习了如何使用 eBPF 来跟踪和统计 TCP 连接建立的延时。我们首先深入探讨了 eBPF 程序如何在内核态监听特定的内核函数,然后通过捕获这些函数的调用,从而得到连接建立的起始时间和结束时间,计算出延时。
我们还进一步了解了如何使用 BPF maps 来在内核态存储和查询数据,从而在 eBPF 程序的多个部分之间共享数据。同时,我们也探讨了如何使用 perf events 来将数据从内核态发送到用户态,以便进一步处理和展示。
在用户态,我们介绍了如何使用 libbpf 库的 API,例如 perf_buffer__poll,来接收和处理内核态发送过来的数据。我们还讲解了如何对这些数据进行解析和打印,使得它们能以人类可读的形式显示出来。
如果您希望学习更多关于 eBPF 的知识和实践,请查阅 eunomia-bpf 的官方文档:https://github.com/eunomia-bpf/eunomia-bpf 。您还可以访问我们的教程代码仓库 https://github.com/eunomia-bpf/bpf-developer-tutorial 或网站 https://eunomia.dev/zh/tutorials/ 以获取更多示例和完整的教程。