eBPF 开发实践:使用 sockops 加速网络请求转发
eBPF(扩展的伯克利数据包过滤器)是 Linux 内核中的一个强大功能,可以在无需更改内核源代码或重启内核的情况下,运行、加载和更新用户定义的代码。这种功能让 eBPF 在网络和系统性能分析、数据包过滤、安全策略等方面有了广泛的应用。
本教程将关注 eBPF 在网络领域的应用,特别是如何使用 sockops 类型的 eBPF 程序来加速本地网络请求的转发。这种应用通常在使用软件负载均衡器进行请求转发的场景中很有价值,比如使用 Nginx 或 HAProxy 之类的工具。
在许多工作负载中,如微服务架构下的服务间通信,通过本机进行的网络请求的性能开销可能会对整个应用的性能产生显著影响。由于这些请求必须经过本机的网络栈,其处理性能可能会成为瓶颈,尤其是在高并发的场景下。为了解决这个问题,sockops 类型的 eBPF 程序可以用于加速本地的请求转发。sockops 程序可以在内核空间管理套接字,实现在本机上的套接字之间直接转发数据包,从而降低了在 TCP/IP 栈中进行数据包转发所需的 CPU 时间。
本教程将会通过一个具体的示例演示如何使用 sockops 类型的 eBPF 程序来加速网络请求的转发。为了让你更好地理解如何使用 sockops 程序,我们将逐步介绍示例程序的代码,并讨论每个部分的工作原理。完整的源代码和工程可以在 https://github.com/eunomia-bpf/bpf-developer-tutorial/tree/main/src/29-sockops 中找到。
利用 eBPF 的 sockops 进行性能优化
网络连接本质上是 socket 之间的通讯,eBPF 提供了一个 bpf_msg_redirect_hash 函数,用来将应用发出的包直接转发到对端的 socket,可以极大地加速包在内核中的处理流程。
这里 sock_map 是记录 socket 规则的关键部分,即根据当前的数据包信息,从 sock_map 中挑选一个存在的 socket 连接来转发请求。所以需要先在 sockops 的 hook 处或者其它地方,将 socket 信息保存到 sock_map,并提供一个规则 (一般为四元组) 根据 key 查找到 socket。
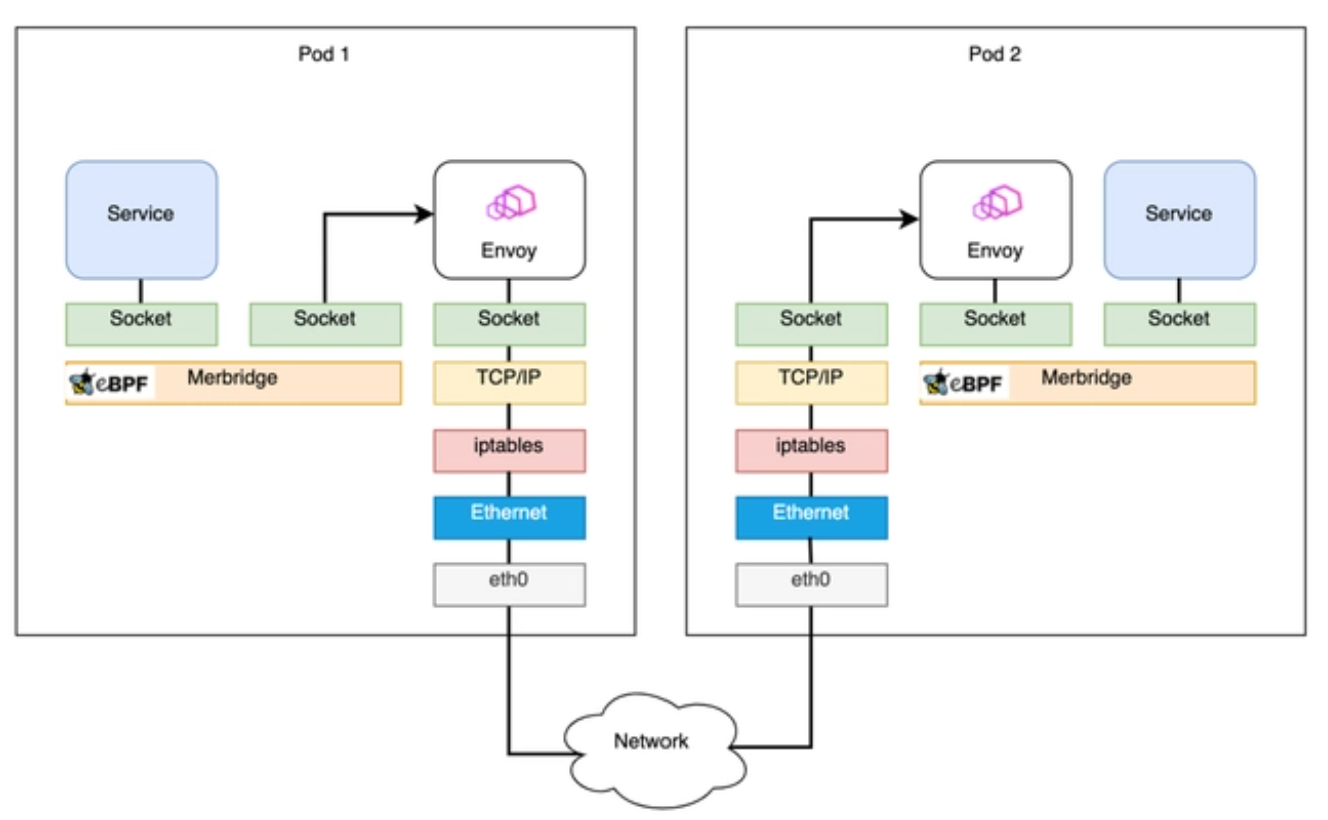
Merbridge 项目就是这样实现了用 eBPF 代替 iptables 为 Istio 进行加速。在使用 Merbridge (eBPF) 优化之后,出入口流量会直接跳过很多内核模块,明显提高性能,如下图所示:
示例程序
此示例程序从发送者的套接字(出口)重定向流量至接收者的套接字(入口),跳过 TCP/IP 内核网络栈。在这个示例中,我们假定发送者和接收者都在同一台机器上运行。这个示例程序有两个部分,它们共享一个 map 定义:
bpf_sockmap.h
#include "vmlinux.h"
#include <bpf/bpf_endian.h>
#include <bpf/bpf_helpers.h>
#define LOCALHOST_IPV4 16777343
struct sock_key {
__u32 sip;
__u32 dip;
__u32 sport;
__u32 dport;
__u32 family;
};
struct {
__uint(type, BPF_MAP_TYPE_SOCKHASH);
__uint(max_entries, 65535);
__type(key, struct sock_key);
__type(value, int);
} sock_ops_map SEC(".maps");这个示例程序中的 BPF 程序被分为两个部分 bpf_redirect.bpf.c 和 bpf_contrack.bpf.c。
-
bpf_contrack.bpf.c中的 BPF 代码定义了一个套接字操作(sockops)程序,它的功能主要是当本机(使用 localhost)上的任意 TCP 连接被创建时,根据这个新连接的五元组(源地址,目标地址,源端口,目标端口,协议),在sock_ops_map这个 BPF MAP 中创建一个条目。这个 BPF MAP 被定义为BPF_MAP_TYPE_SOCKHASH类型,可以存储套接字和对应的五元组。这样使得每当本地 TCP 连接被创建的时候,这个连接的五元组信息也能够在 BPF MAP 中找到。 -
bpf_redirect.bpf.c中的 BPF 代码定义了一个网络消息 (sk_msg) 处理程序,当本地套接字上有消息到达时会调用这个程序。然后这个 sk_msg 程序检查该消息是否来自本地地址,如果是,根据获取的五元组信息(源地址,目标地址,源端口,目标端口,协议)在sock_ops_map查找相应的套接字,并将该消息重定向到在sock_ops_map中找到的套接字上,这样就实现了绕过内核网络栈。
举个例子,我们假设有两个进程在本地运行,进程 A 绑定在 8000 端口上,进程 B 绑定在 9000 端口上,进程 A 向进程 B 发送消息。
-
当进程 A 首次和进程 B 建立 TCP 连接时,触发
bpf_contrack.bpf.c中的sockops程序,这个程序将五元组{127.0.0.1, 127.0.0.1, 8000, 9000, TCP}存入sock_ops_map,值为进程 A 的套接字。 -
当进程 A 发送消息时,触发
bpf_redirect.bpf.c中的sk_msg程序,然后sk_msg程序将消息从进程 A 的套接字重定向到sock_ops_map中存储的套接字(进程 A 的套接字)上,因此,消息被直接从进程 A 输送到进程 B,绕过了内核网络栈。
这个示例程序就是通过 BPF 实现了在本地通信时,快速将消息从发送者的套接字重定向到接收者的套接字,从而绕过了内核网络栈,以提高传输效率。
bpf_redirect.bpf.c
#include "bpf_sockmap.h"
char LICENSE[] SEC("license") = "Dual BSD/GPL";
SEC("sk_msg")
int bpf_redir(struct sk_msg_md *msg)
{
if(msg->remote_ip4 != LOCALHOST_IPV4 || msg->local_ip4!= LOCALHOST_IPV4)
return SK_PASS;
struct sock_key key = {
.sip = msg->remote_ip4,
.dip = msg->local_ip4,
.dport = bpf_htonl(msg->local_port), /* convert to network byte order */
.sport = msg->remote_port,
.family = msg->family,
};
return bpf_msg_redirect_hash(msg, &sock_ops_map, &key, BPF_F_INGRESS);
}bpf_contrack.bpf.c
#include "bpf_sockmap.h"
char LICENSE[] SEC("license") = "Dual BSD/GPL";
SEC("sockops")
int bpf_sockops_handler(struct bpf_sock_ops *skops){
u32 family, op;
family = skops->family;
op = skops->op;
if (op != BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB
&& op != BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB) {
return BPF_OK;
}
if(skops->remote_ip4 != LOCALHOST_IPV4 || skops->local_ip4!= LOCALHOST_IPV4) {
return BPF_OK;
}
struct sock_key key = {
.dip = skops->remote_ip4,
.sip = skops->local_ip4,
.sport = bpf_htonl(skops->local_port), /* convert to network byte order */
.dport = skops->remote_port,
.family = skops->family,
};
bpf_printk(">>> new connection: OP:%d, PORT:%d --> %d\n", op, bpf_ntohl(key.sport), bpf_ntohl(key.dport));
bpf_sock_hash_update(skops, &sock_ops_map, &key, BPF_NOEXIST);
return BPF_OK;
}编译 eBPF 程序
这里我们使用 libbpf 编译这个 eBPF 程序。完整的源代码和工程可以在 https://github.com/eunomia-bpf/bpf-developer-tutorial/tree/main/src/29-sockops 中找到。关于如何安装依赖,请参考:https://eunomia.dev/tutorials/11-bootstrap/
# Compile the bpf program with libbpf
make加载 eBPF 程序
我们编写了一个脚本来加载 eBPF 程序,它会自动加载两个 eBPF 程序并创建一个 BPF MAP:
sudo ./load.sh这个脚本实际上完成了这些操作:
#!/bin/bash
set -x
set -e
sudo mount -t bpf bpf /sys/fs/bpf/
# check if old program already loaded
if [ -e "/sys/fs/bpf/bpf_sockops" ]; then
echo ">>> bpf_sockops already loaded, uninstalling..."
./unload.sh
echo ">>> old program already deleted..."
fi
# load and attach sock_ops program
sudo bpftool prog load bpf_contrack.bpf.o /sys/fs/bpf/bpf_sockops type sockops pinmaps /sys/fs/bpf/
sudo bpftool cgroup attach "/sys/fs/cgroup/" sock_ops pinned "/sys/fs/bpf/bpf_sockops"
# load and attach sk_msg program
sudo bpftool prog load bpf_redirect.bpf.o "/sys/fs/bpf/bpf_redir" map name sock_ops_map pinned "/sys/fs/bpf/sock_ops_map"
sudo bpftool prog attach pinned /sys/fs/bpf/bpf_redir msg_verdict pinned /sys/fs/bpf/sock_ops_map这是一个 BPF 的加载脚本。它的主要功能是加载和附加 BPF 程序到内核系统中,并将关联的 BPF map 一并存储(pin)到 BPF 文件系统中,以便 BPF 程序能访问和操作这些 map。
让我们详细地看一下脚本的每一行是做什么的。
sudo mount -t bpf bpf /sys/fs/bpf/这一行用于挂载 BPF 文件系统,使得 BPF 程序和相关的 map 可以被系统访问和操作。- 判断条件
[ -e "/sys/fs/bpf/bpf_sockops" ]是检查是否已经存在/sys/fs/bpf/bpf_sockops文件,如果存在,则说明bpf_sockops程序已经被加载到系统中,那么将会通过./unload.sh脚本将其卸载。 sudo bpftool prog load bpf_contrack.bpf.o /sys/fs/bpf/bpf_sockops type sockops pinmaps /sys/fs/bpf/这一行是加载上文中bpf_contrack.bpf.c编译得到的 BPF 对象文件bpf_contrack.bpf.o到 BPF 文件系统中,存储至/sys/fs/bpf/bpf_sockops,并且指定它的类型为sockops。pinmaps /sys/fs/bpf/是指定将加载的 BPF 程序相关的 map 存储在/sys/fs/bpf/下。sudo bpftool cgroup attach "/sys/fs/cgroup/" sock_ops pinned "/sys/fs/bpf/bpf_sockops"这一行是将已经加载到 BPF 文件系统的bpf_sockops程序附加到 cgroup(此路径为"/sys/fs/cgroup/")。附加后,所有属于这个 cgroup 的套接字操作都会受到bpf_sockops的影响。sudo bpftool prog load bpf_redirect.bpf.o "/sys/fs/bpf/bpf_redir" map name sock_ops_map pinned "/sys/fs/bpf/sock_ops_map"这一行是加载bpf_redirect.bpf.c编译得到的 BPF 对象文件bpf_redirect.bpf.o到 BPF 文件系统中,存储至/sys/fs/bpf/bpf_redir,并且指定它的相关 map为sock_ops_map,这个map在/sys/fs/bpf/sock_ops_map中。sudo bpftool prog attach pinned /sys/fs/bpf/bpf_redir msg_verdict pinned /sys/fs/bpf/sock_ops_map这一行是将已经加载的bpf_redir附加到sock_ops_map上,附加方式为msg_verdict,表示当该 map 对应的套接字收到消息时,将会调用bpf_redir程序处理。
综上,此脚本的主要作用就是将两个用于处理本地套接字流量的 BPF 程序分别加载到系统并附加到正确的位置,以便它们能被正确地调用,并且确保它们可以访问和操作相关的 BPF map。
您可以使用 bpftool utility 检查这两个 eBPF 程序是否已经加载。
$ sudo bpftool prog show
63: sock_ops name bpf_sockops_handler tag 275467be1d69253d gpl
loaded_at 2019-01-24T1317+0200 uid 0
xlated 1232B jited 750B memlock 4096B map_ids 58
64: sk_msg name bpf_redir tag bc78074aa9dd96f4 gpl
loaded_at 2019-01-24T1317+0200 uid 0
xlated 304B jited 233B memlock 4096B map_ids 58使用 iperf3 或 curl 进行测试
运行 iperf3 服务器
iperf3 -s -p 5001运行 iperf3 客户端
iperf3 -c 127.0.0.1 -t 10 -l 64k -p 5001或者也可以用 Python 和 curl 进行测试:
python3 -m http.server
curl http://0.0.0.0:8000/收集追踪
查看sock_ops追踪本地连接建立
$ ./trace_bpf_output.sh # 实际上就是 sudo cat /sys/kernel/debug/tracing/trace_pipe
iperf3-9516 [001] .... 22500.634108: 0: <<< ipv4 op = 4, port 18583 --> 4135
iperf3-9516 [001] ..s1 22500.634137: 0: <<< ipv4 op = 5, port 4135 --> 18583
iperf3-9516 [001] .... 22500.634523: 0: <<< ipv4 op = 4, port 19095 --> 4135
iperf3-9516 [001] ..s1 22500.634536: 0: <<< ipv4 op = 5, port 4135 --> 19095当iperf3 -c建立连接后,你应该可以看到上述用于套接字建立的事件。如果你没有看到任何事件,那么 eBPF 程序可能没有正确地附加上。
此外,当sk_msg生效后,可以发现当使用 tcpdump 捕捉本地lo设备流量时,只能捕获三次握手和四次挥手流量,而iperf数据流量没有被捕获到。如果捕获到iperf数据流量,那么 eBPF 程序可能没有正确地附加上。
$ ./trace_lo_traffic.sh # tcpdump -i lo port 5001
# 三次握手
1307.181804 IP localhost.46506 > localhost.5001: Flags [S], seq 620239881, win 65495, options [mss 65495,sackOK,TS val 1982813394 ecr 0,nop,wscale 7], length 0
1307.181815 IP localhost.5001 > localhost.46506: Flags [S.], seq 1084484879, ack 620239882, win 65483, options [mss 65495,sackOK,TS val 1982813394 ecr 1982813394,nop,wscale 7], length 0
1307.181832 IP localhost.46506 > localhost.5001: Flags [.], ack 1, win 512, options [nop,nop,TS val 1982813394 ecr 1982813394], length 0
# 四次挥手
1312.475649 IP localhost.46506 > localhost.5001: Flags [F.], seq 1, ack 1, win 512, options [nop,nop,TS val 1982818688 ecr 1982813394], length 0
1312.479621 IP localhost.5001 > localhost.46506: Flags [.], ack 2, win 512, options [nop,nop,TS val 1982818692 ecr 1982818688], length 0
1312.481265 IP localhost.5001 > localhost.46506: Flags [F.], seq 1, ack 2, win 512, options [nop,nop,TS val 1982818694 ecr 1982818688], length 0
1312.481270 IP localhost.46506 > localhost.5001: Flags [.], ack 2, win 512, options [nop,nop,TS val 1982818694 ecr 1982818694], length 0卸载 eBPF 程序
sudo ./unload.sh参考资料
最后,如果您对 eBPF 技术感兴趣,并希望进一步了解和实践,可以访问我们的教程代码仓库 https://github.com/eunomia-bpf/bpf-developer-tutorial 和教程网站 https://eunomia.dev/zh/tutorials/
原文地址:https://eunomia.dev/zh/tutorials/29-sockops/ 转载请注明出处。
继续阅读
返回索引
eBPF 开发实践教程:基于 CO-RE,通过小工具快速上手 eBPF 开发
这是一个基于 CO-RE(一次编译,到处运行)的 eBPF 的开发教程,提供了从入门到进阶的 eBPF 开发实践,包括基本概念、代码实例、实际应用等内容。和 BCC 不同的是,我们使用 libbpf、Cilium、libbpf-rs、eunomia-bpf 等框架进行开发,包含 C、Go、Rust 等语言的示例。
上一篇 / 上一页
在应用程序退出后运行 eBPF 程序:eBPF 程序的生命周期
eBPF(Extended Berkeley Packet Filter)是 Linux 内核中的一项重大技术创新,允许用户在内核空间中执行自定义程序,而无需修改内核源代码或加载任何内核模块。这为开发人员提供了极大的灵活性,可以观察、修改和控制 Linux 系统。
下一篇 / 下一页
eBPF 实践教程:使用 uprobe 捕获多种库的 SSL/TLS 明文数据
随着TLS在现代网络环境中的广泛应用,跟踪微服务RPC消息已经变得愈加棘手。传统的流量嗅探技术常常受限于只能获取到加密后的数据,导致无法真正观察到通信的原始内容。这种限制为系统的调试和分析带来了不小的障碍。
- 最后更新
- 2025年8月24日
- 首次发布
- 2023年8月10日
- 贡献者
- yunwei37, 云微, oluceps
这个页面有帮助吗?